Preempting the Prefill, Part 3: Results & Benchmark
Part 2 walked through the components that make slack-aware preemption work in vLLM, the design decisions that diverge from the paper, and the reasoning behind each. This last post in the series covers the benchmark setup and what we measured.
Benchmark design
| Section | Parameter | Value |
|---|---|---|
| Hardware & topology | Hardware | 6× A100 SXM4 80GB on RunPod |
| Model | Llama 70B (bf16) | |
| Prefill | TP = 4 | |
| Decode | TP = 2 | |
| KV transfer | NIXL | |
| Workload | Prompts | ShareGPT, 256–8000 tokens |
| Decode cap | 4 tokens per request (TTFT is the metric) | |
| Tier mix | 20% urgent, 80% generous | |
| Urgent SLO band | [1.0, 1.3] × baseline TTFT | |
| Generous SLO band | [3, 10] × baseline TTFT | |
| Arrivals | Poisson | |
| Predictor | TTFT predictor | a = 0.173 ms/tok, c = 34 ms (refit per model/hardware/TP) |
| Measurement | Window | 30 s warmup + 300 s recorded |
| Policies | control (FCFS), conservative, aggressive | |
| Trials | 5 paired per (rate, policy) cell |
A few notes on the setup itself:
- TP split: 4 shards on prefill, 2 on decode follows from capping each request at 4 decode tokens. TTFT is the metric, so per-request decode work is bounded, so the decode node doesn’t need as many shards as the prefill node, where compute dominates.
- KV transfer via NIXL: prefill and decode live on physically separate GPUs, so KV blocks have to move across once prefill finishes (NIXL is vLLM’s standard RDMA connector for that handoff).
- ShareGPT for prompts: real ChatGPT conversations, and the de facto vLLM benchmark workload (right length distribution and the community precedent that makes the numbers comparable).
- SLO bands: multipliers on each request’s own baseline TTFT, so an urgent request at 500 tokens and one at 5000 tokens both get a band that’s tight against their own work, not against a single absolute number that’s wrong for both.


Filter and refit are one-time setup; the measurement loop then spins through every (rate × policy × trial) combination. The predictor’s coefficients are hardware-specific. The refit step measures them on this exact setup before the runs start, so slack is honest. Skip it and every preempt decision is acting on a biased estimate.


Within a cell, the same arrival stream replays against control, conservative, and aggressive, so any attainment gap is the policy, not the prompts. Five trials per cell average out the residual noise.
Results
Once the mechanism is wired end-to-end, the SLO monitor flags an intent, the workers vote across ranks at every attention boundary, and the preempted request unwinds:
[slo_monitor] PREEMPT INTENT (route=in-batch, step_id=8421):
waiting req-94 (tokens=2048 slack=-115.3ms ttft_pred=388.2ms prio=8.7e-04)
would displace
running req-89 (tokens=5120 slack=+412.7ms ttft_pred=920.4ms prio=2.4e-03)
[margin=1.20x, snapshot_age=42.1ms, stubborn=0/4]
[preempt_check] rank=0 layer=layers.18.attn layer_idx=18/80
vote=1 target_step=8421 current_step=8421
Each policy fires as often as its rules allow: aggressive fires throughout the sweep; conservative rarely does, since it only preempts when a waiter is much more urgent than all the running requests.
Sweeping the request rate from 2 to 10 req/s:
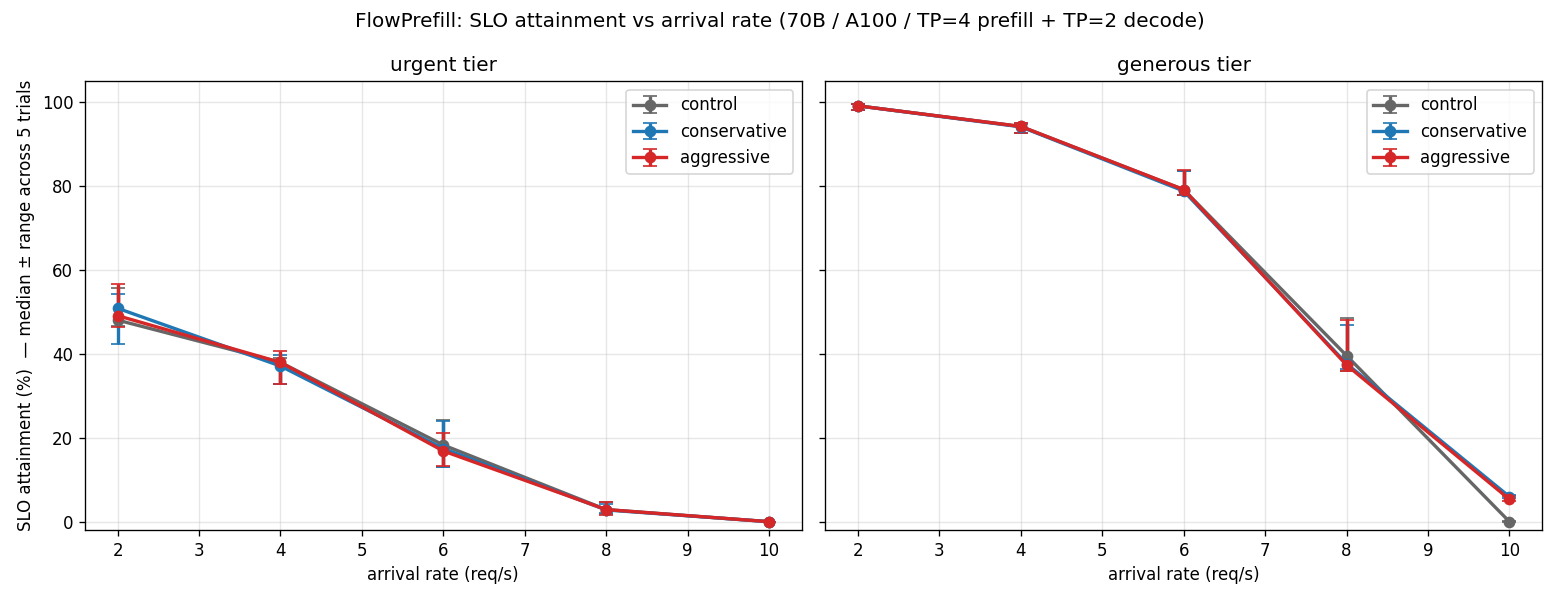
Below saturation (rates 2–8) the three policies sit within ±2 percentage points of each other on urgent attainment, identical on generous.
The intuition is a single checkout line with one cashier who takes the same time per customer regardless of order. If everyone has slack on their deadline, letting an urgent customer cut just moves the slack around (nobody was going to miss anyway).
The interesting cell is rate 10. Control collapses (effectively no request meets its SLO). Both FlowPrefill policies pull a few percentage points of rescue:
| Policy | Goodput (req/s) | Urgent attainment % | Generous attainment % |
|---|---|---|---|
| control | 0.001 | 0.00 | 0.02 |
| conservative | 0.323 | 0.82 | 3.86 |
| aggressive | 0.443 | 2.24 | 5.02 |
That’s roughly 300–450× control’s goodput at the saturation point. Control is FCFS: it serves the oldest request first, which under saturation is also the one whose deadline already passed. By the time it finishes that one, the request behind it is also past deadline, and so on; every request inherits the same fate. FlowPrefill breaks the chain by doing load shedding inside the prefill phase: abandoning work that was going to miss anyway to free the GPU for work that can still meet its deadline.
The rescue lands mostly on the generous tier: those requests have wide enough SLO bands to still be saveable when the queue is deep. Urgent waiters at rate 10 are mostly past saving by the time the monitor sees them, and the policy explicitly refuses to fire a preempt for a doomed waiter (the wasted re-prefill cost would exceed any possible save). So the urgent-tier rescue is real but small (0.82% / 2.24% in aggregate), and the bulk of the lift comes from saving the wider-band generous requests that can still be helped.
What I ruled out
To check whether FlowPrefill could have helped more with different tuning, I swept both the SLO band and the stubbornness threshold, and neither moved the result.
First, the urgent SLO band. If urgent SLOs were generous enough that requests met deadline without help, narrowing the band should increase goodput attainment. At rate 6, I swept the urgent multiplier from 1.0× to 3.0×:
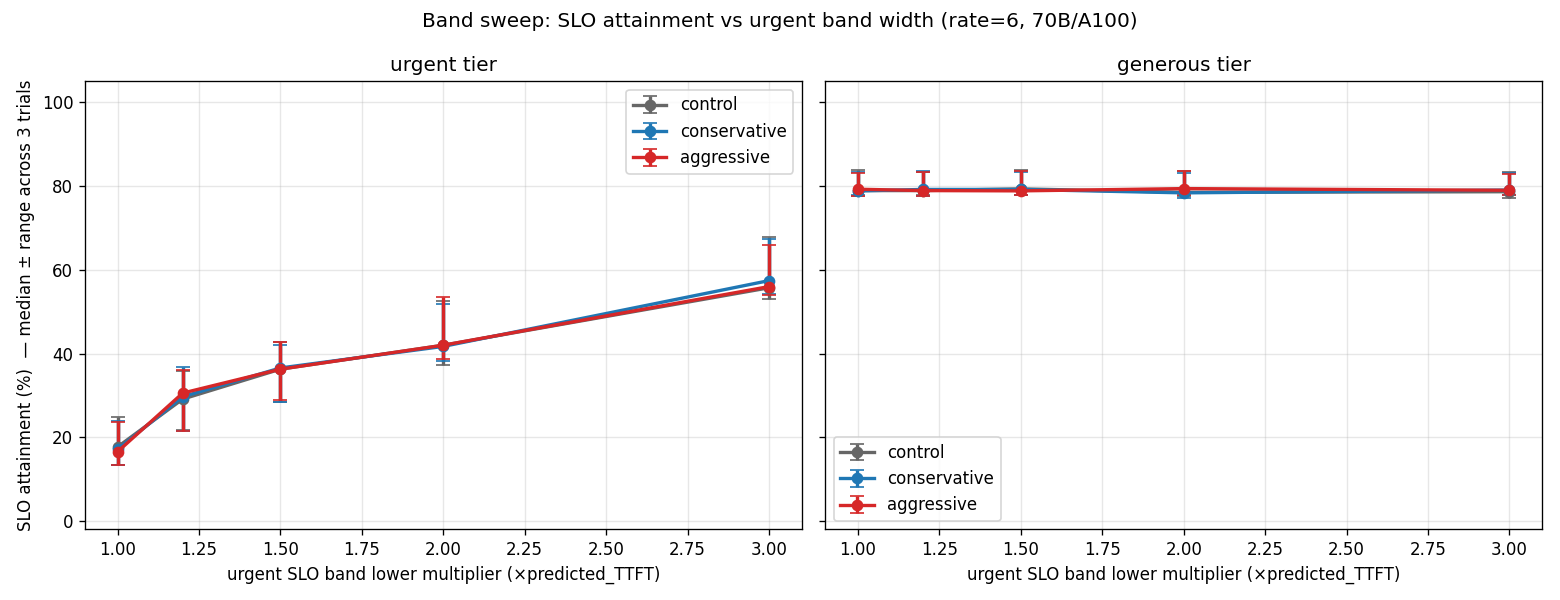
Attainment does rise as the band widens (that’s expected), but the three policies move together across the whole sweep (band-tightness isn’t the cap).
Second, the stubbornness threshold. Rule 2’s layer-fraction threshold (default 0.9) blocks preempts past 90% of the forward pass. If that’s where useful preempts live, lowering it should increase goodput attainment. I swept the threshold over {0.0, 0.5, 0.9} at rate 8, and the three policies moved together across all three thresholds, with no increase in goodput attainment (stubbornness isn’t the cap either).
Scope and what’s next
This ran on a fixed setup: Llama 70B on A100 (TP=4 prefill, TP=2 decode), serving ShareGPT prompts with Poisson arrivals. Moreover, chunked prefill was off and prefix caching was disabled. The same reasoning should apply more broadly, but I haven’t tested:
- Heavier-tailed arrivals (Poisson bursts are brief, but heavier-tailed traffic could create longer periods of deep queue where FlowPrefill might actually help, even when the overall rate stays below saturation).
- Chunked prefill on (vLLM’s production default). The current implementation requires it off.
- Other models or hardware (TTFT coefficients are GPU-specific, though the policy choices aren’t).
The fork is on GitHub at adiu19/vllm.
Enjoy Reading This Article?
Here are some more articles you might like to read next: