Peer-to-Peer Caching for FUSE-Backed Content Stores, Part 1
Modal published a blog post in May 2026 about their serverless GPU stack. Cold-starting a container on a GPU worker means pulling its filesystem first (image layers and model weights), so the bytes a container reads come from a cache hierarchy instead of object storage on every boot. One line about that hierarchy stood out:
“To really make this rip, you might build more layers between SSD and object storage, like an RDMA layer or within-AZ peer-to-peer sharing. Both are compelling on the numbers, but add a lot of engineering complexity, so we haven’t added them — yet.”
The unbuilt tier they’re calling out: when a worker misses its local SSD cache, the fall-through is the AZ cache server at ~1ms. There’s another worker right next door, on the same intra-AZ network, probably already holding the same blob. Why not ask that worker first?
This two-part series measures that. Part 1 (this post) is the groundwork: how much does going through FUSE cost compared to going through a kernel filesystem? What’s the per-op overhead, and how does it scale with concurrency? Part 2 builds the P2P layer and measures whether fetching from a peer actually beats the centralized fall-through, and whether the coordination overhead eats the savings.
Why FUSE
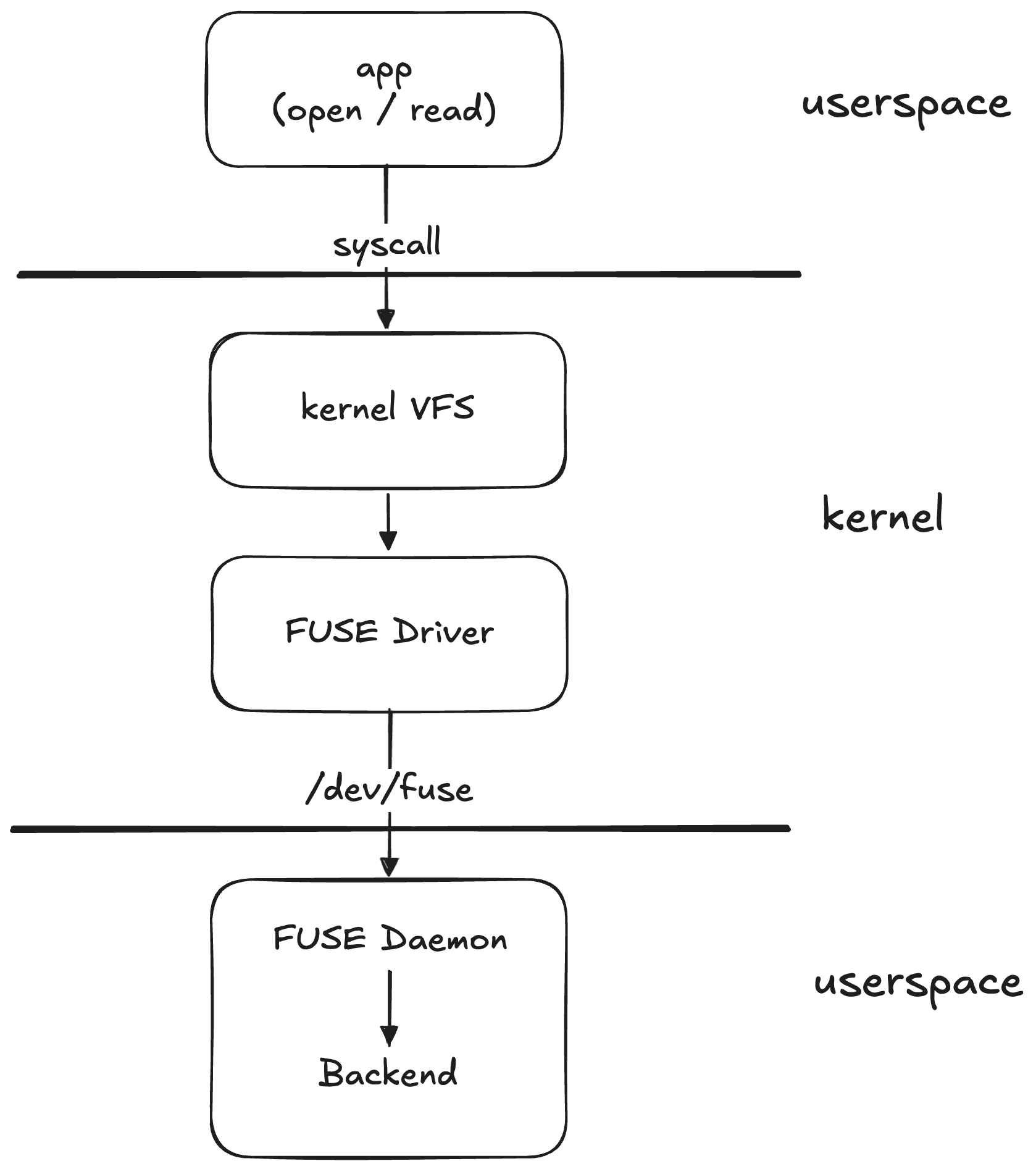
Apps open() files and read() bytes, and they don’t know what’s underneath. To serve them custom data without changing them, we need to look like a filesystem.
FUSE lets us do that: the kernel keeps its VFS abstraction while a userspace daemon implements the ops over a /dev/fuse channel. The daemon can do anything (fetch from the network, lazy-load) and the kernel doesn’t care.
The cost is the round trip: every read() walks app → kernel → daemon → kernel → app, which is two context switches and tens of microseconds at minimum. Whether that cost matters depends on what we’re hiding behind it.
The setup
I’ve been building chorus for a while: it started as a gossip cluster, grew into a replicated KV store, then more pieces on top. The point of chorus, to me, was never any specific feature. It was to find out whether I could combine the primitives without coupling them (and help me benchmark things!).
For part 1, only one of those primitives matters: the pluggable FUSE backend, which mounts a filesystem and serves bytes from an in-memory map. The full worker architecture (gossip, replicated KV for discovery, peer-fetch transport) lands in part 2, when there’s actually a cluster to talk about.
How we measure
We measure what an app would feel: open() and read() syscalls against the mount, timed at the syscall boundary. That’s a specific workload, so we wrote a specific harness (a Go program that opens hash-named files and reads their bytes). The corpus is N deterministic random blobs, each named by sha256(bytes). The daemon and harness derive the same hash list from a shared seed, with no coordination at startup.
The baseline is tmpfs with the same harness and workload, so the gap between FUSE p99 and tmpfs p99 is exactly the cost of the FUSE round trip, with nothing else varying.
We run each configuration 10 times, take the p99 within each run, then report the median of those 10 p99s. The concurrency sweep covers 1, 4, 16, 64, and 256 readers, on a box with 4 dedicated vCPU and 16 GB of RAM.
What we found
At a single reader, FUSE adds ~85µs to open() and ~58µs to read() over tmpfs: what every FUSE-backed system pays per op with no contention. Under load it diverges: tmpfs stays flat at ~11µs across the entire concurrency range, while FUSE grows nearly linearly, reaching a 72ms p99 at 256 readers.
The shape is interesting too: tmpfs is flat because the kernel parallelizes filesystem ops natively; FUSE isn’t, because every request flows through one /dev/fuse channel to one daemon process.
That single path seems to be the bottleneck, and any FUSE-backed system that wants to scale has to tackle it: more channels, more daemon threads, or enough caching that most reads never reach the daemon at all.
What comes next
The follow-up question, which part 2 measures: when the bytes aren’t local, where should they come from? The shared cache server everyone falls through to, or a peer that already holds the bytes? How does that choice affect end-to-end latency at realistic concurrency?
Enjoy Reading This Article?
Here are some more articles you might like to read next: